
Mocne karty graficzne potrafią dziś kosztować 8-12 tys. zł. Jeśli myślicie o pracy z modelami LLM, generowaniu obrazów czy eksperymentowaniu z własnymi środowiskami AI – szybko okazuje się, że to właśnie sprzęt jest największą barierą wejścia, a nie wiedza.
Istnieje jednak inna droga.
Zamiast kupować GPU za 10 tys. zł, możecie wynająć podobną klasę mocy obliczeniowej w chmurze i płacić wyłącznie za czas, w którym faktycznie z niej korzystacie. Na start wystarczy kilkadziesiąt dolarów, żeby sprawdzić, czy AI jest dla Was narzędziem, zabawką, czy może nowym kierunkiem rozwoju.
Ten artykuł nie jest instrukcją krok po kroku, lecz wyjaśnieniem – jak działa model wynajmu GPU w chmurze, jak wygląda płatność i jakie możliwości daje platforma taka jak Runpod.
Dlaczego nie lokalnie?
Oczywiście da się uruchomić mniejsze modele na słabszym sprzęcie. Problem zaczyna się wtedy, gdy:
- chcecie pracować z większymi modelami LLM;
- zależy Wam na sensownym czasie odpowiedzi;
- generujecie obrazy w wyższej rozdzielczości;
- testujecie różne konfiguracje.
Kluczowym parametrem jest VRAM – pamięć karty graficznej. To ona w praktyce decyduje, jak duży model możecie uruchomić i jak stabilnie będzie działał.
Zakup GPU to koszt jednorazowy, ale wysoki. Chmura rozwiązuje ten problem inaczej: zamienia wydatek inwestycyjny na koszt operacyjny.
Runpod – GPU na żądanie
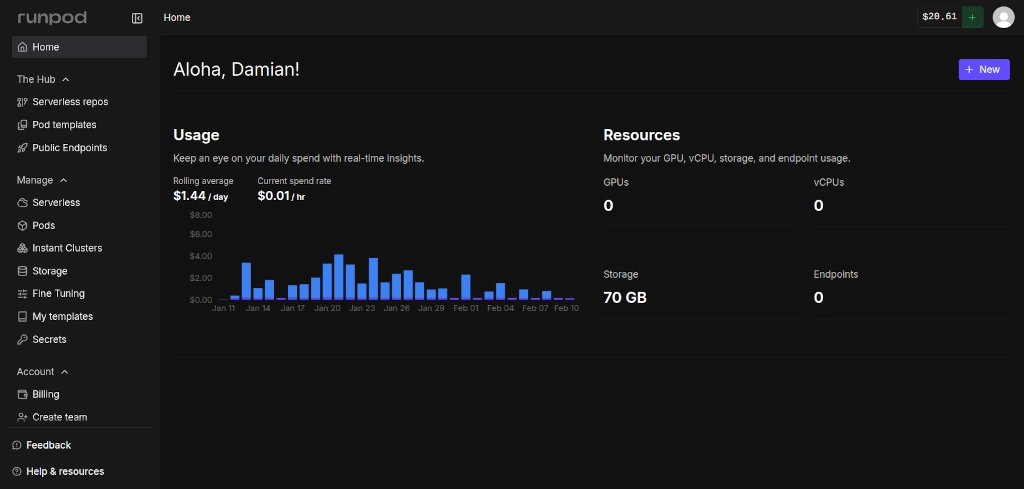
Runpod to platforma umożliwiająca wynajem GPU. Nie kupujecie sprzętu – wynajmujecie dostęp do niego na czas pracy.
Najważniejsze cechy tego modelu:
- płacicie za realny czas działania instancji,
- możecie dobrać konkretny typ GPU do zadania,
- nie ponosicie kosztów, gdy nic nie jest uruchomione,
- w każdej chwili możecie zakończyć korzystanie z usługi.
To rozwiązanie szczególnie sensowne, jeśli:
- pracujecie projektowo;
- testujecie różne modele;
- nie potrzebujecie stałego dostępu do mocy obliczeniowej 24/7.
Jak działa Runpod?
Run pod bazuje na kontenerach – czyli gotowych, odizolowanych środowiskach zawierających system, zależności i wybrane narzędzie.
W praktyce oznacza to, że możecie uruchomić gotowe środowisko z LLM, ComfyUI, Jupyterem czy innym narzędziem bez ręcznej konfiguracji sterowników i bibliotek.
Platforma oferuje trzy główne sposoby korzystania z zasobów:
Public Endpoint
Gotowe modele hostowane przez platformę. Korzystacie z nich przez panel lub API i płacicie za zapytania.
To dobre rozwiązanie, jeśli interesuje Was tylko dostęp do modelu, bez zarządzania infrastrukturą.
Serverless
Rozwiązanie pośrednie – płatność następuje wyłącznie za czas wykonywania zapytań. Gdy nikt nie korzysta z endpointu, koszt wynosi zero.
To opcja atrakcyjna przy integracji z aplikacją, np. gdy macie narzędzie i model przygotowane pod konkretne zadania.
Pod
Pod to dedykowana instancja GPU lub CPU. W praktyce wynajmujecie konkretną maszynę z określoną ilością VRAM, RAM, CPU i GPU.
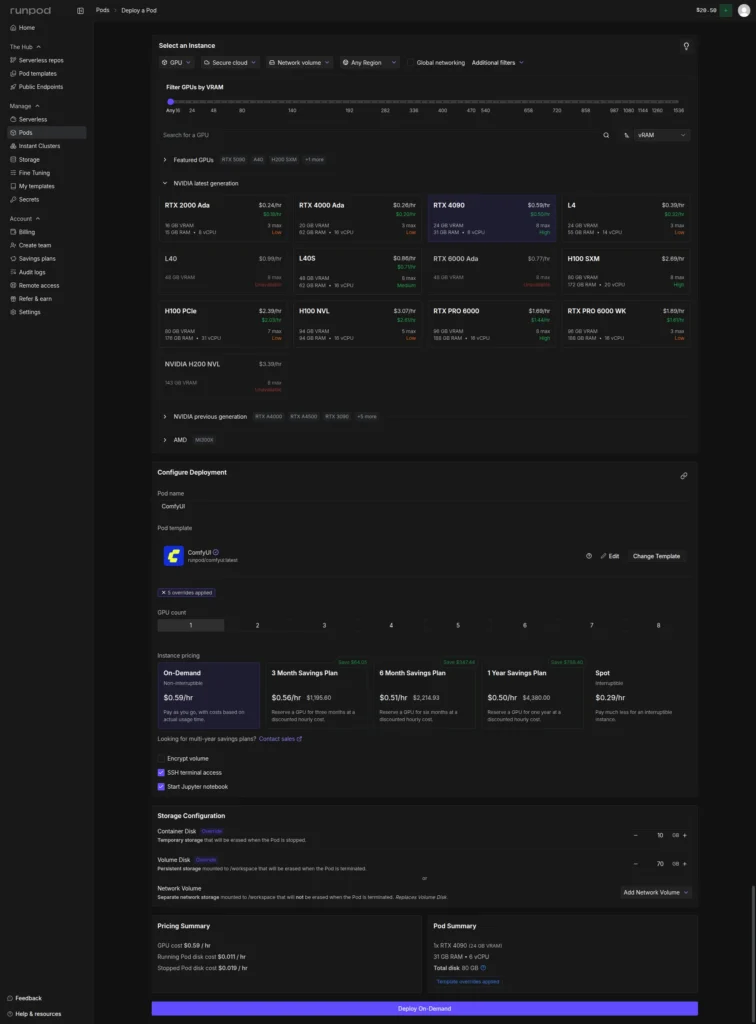
To rozwiązanie daje największą kontrolę – możecie uruchamiać kontenery według potrzeb, zarządzać nimi i narzędziami wewnątrz nich. Macie dostęp do maszyny, a nie jedynie endpoint, który wykonuje konkretne zadanie.
Koszt naliczany jest za czas działania instancji. Możecie ją zatrzymać, płacąc tylko za przechowywanie danych, albo usunąć całkowicie.
Jak wygląda model płatności?
Nie ma abonamentu, subskrypcji ani stałej opłaty za konto.
Zasilacie saldo i z niego rozliczany jest czas działania instancji lub liczba zapytań (w zależności od trybu).
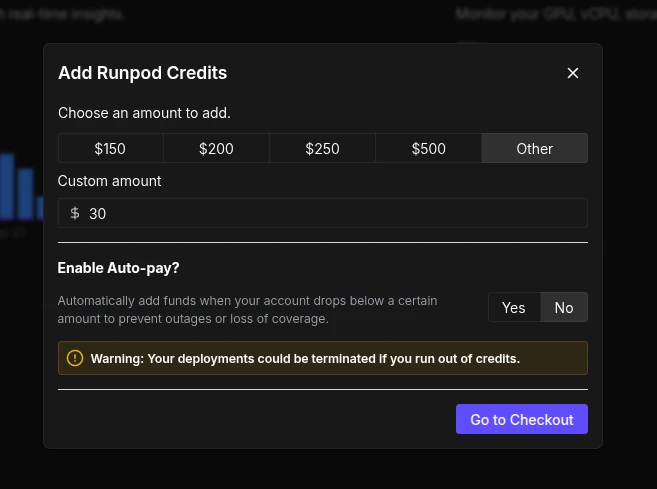
Najważniejsze z perspektywy kosztów:
- cena zależy od typu GPU;
- płacicie za czas pracy instancji lub zapytanie (w zależności od trybu);
- po zatrzymaniu instancji przestajecie płacić za GPU;
- po usunięciu instancji nie ma dalszych kosztów.
Dzięki temu łatwo kontrolować budżet – szczególnie na etapie testów.
Przechowywanie danych
Modele AI potrafią zajmować dziesiątki gigabajtów. Dlatego istotnym elementem jest sposób przechowywania danych.
W uproszczeniu:
- część przestrzeni jest tymczasowa (systemowa);
- część może być trwała (na modele i projekty).
Możliwe jest też korzystanie z wolumenów sieciowych, które pozwalają zachować dane niezależnie od konkretnej instancji.
To szczególnie przydatne, jeśli nie chcecie być przywiązani do jednej konkretnej instancji i jednocześnie nie tracić czasu na ponowne pobieranie modeli.
Czy to się opłaca?
Jeśli planujecie wieloletnią, codzienną pracę z dużymi modelami – zakup własnego GPU będzie mieć sens ekonomiczny.
Jeśli jednak:
- dopiero zaczynacie;
- eksperymentujecie;
- pracujecie nieregularnie;
- chcecie sprawdzić różne konfiguracje;
wynajem GPU w chmurze jest znacznie bardziej elastyczny i bezpieczny finansowo.
Zamiast podejmować decyzję o zakupie sprzętu w ciemno, możecie najpierw zrozumieć swoje realne potrzeby i przetestować konkretne konfiguracje pod kątem wydajności w poszczególnych zadaniach.
Podsumowanie
Wejście w świat AI nie musi oznaczać dużej inwestycji w sprzęt.
Model chmurowy pozwala zamienić koszt zakupu na koszt testu. Kilkadziesiąt dolarów wystarczy, aby realnie sprawdzić możliwości modeli LLM, generowania obrazów czy własnych projektów.
A dopiero potem – jeśli faktycznie będzie to potrzebne – można myśleć o własnym GPU. Może się też okazać, że model chmurowy będzie dla Was wciąż bardziej opłacalny, nawet w dłuższym okresie.
Najpierw praktyka. Sprzęt zawsze można kupić później.